
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | ||||||
| 2 | 3 | 4 | 5 | 6 | 7 | 8 |
| 9 | 10 | 11 | 12 | 13 | 14 | 15 |
| 16 | 17 | 18 | 19 | 20 | 21 | 22 |
| 23 | 24 | 25 | 26 | 27 | 28 | 29 |
| 30 |
- 주석
- fibo
- 오픽점수잘받는방법
- 오픽가격
- 이진탐색 #나무 자르기
- 바텀업
- English
- 오픽노잼
- 이진탐색
- ㅂ
- 디피
- 다이나믹프로그래밍
- 오픽노잼공부방법
- 탑다운
- 오픽
- XML
- dynamicProgramming
- dp
- 메모이제이션
- 오픽공부법
- 안드로이드
- stack 스택
- 영어회화
- 영어말하기
- topdown
- 피보나치수열
- opic
- XML주석
- 안드로이드주석
RUBY
[R]5. 분할정복: 의사결정 트리와 규칙 기반의 분류 본문
트리와 규칙이 데이터를 관심있는 세그먼트로 ‘탐욕스럽게 ’ 분할하는 방법
C5.0, 1R,RIPPER 알고리즘을 포함하는 가장 보편적인 의사결정 트리와 분류 규칙 학습자
위험 은행 대출과 독버섯 식별과 같은 실제 분류 작업을 수행하기 위한 알고리즘 사용 방법
의사결정 트리의 이해
▶의사결정 트리 학습자 : 강력한 분류기, 특징과 잠재적 결과 간의 관계를 모델링 하기 위해 트리 구조 활용
▶의사결정 트리 분류기: 예시를 최종 예측 클래스 값으로 보내기 위해 결정을 분기 시키는 구조를 사용한다.
EX) 일자리제안 수락 여부에 대한 의사 결정 트리
root node(루트 노드): 고려중인 일자리 제안
decision node(결정 노드): 직업의 속성에 따라 선택이 이뤄짐
branches(분기): 결정의 잠재적 결과를 나타내는 분기로 데이터 분할, 분기는 두 개 이상 가능
leaf nodes/terminal nodes (잎 노드/ 터미널 노드): 최종 결정
▶의사결정 트리 알고리즘
-장점) 플로 차트 같은 트리 구조가 학습자의 내부적인 용도로만 사용되지 않는다.
-대다수 의사결정 트리 알고리즘은 모델이 생성된 이후 생성된 구조를 사람이 읽을 수 있는 형식으로 출력
-용도)법적인 이유로 분류 방법이 투명해야 하는 애플리케이션, 향후 업무를 알리기 위해 다른 사람과 결과를 공유해야 해는 경우
〮신청자 거절 기준이 명확히 문서화되고 편향되지 않은 신용평가 모델
〮경영진 또는 광고 대행사와 공유될 고객 만족이나 고객 이탈과 같은 고객 행동 마케팅 연구
〮실험실 측정, 증상, 질병 진행률을 기반으로 하는 질병 진단
-의사결정 트리는 가장 널리 사용되는 하나의 머신 러닝 기법, 거의 모든 종류의 데이터를 모델링하는데 적용
-의사결정 트리가 데이터에 과적합 되는 경향 주의해야함
분할 정복
▶분할 정복(divide and conquer) : 데이터를 부분 집합으로 나누고 그 다음 더 작은 부분집합으로 반복해서 나누며, 알고리즘이 부분 집합의 데이터가 충분히 동질적이라고 판단하거나 다른 종료 조건을 만나서 과정이 종료될 때까지 계속됨
▶ 의사결정 트리는 재귀분할(recursive partitioning)이라고 하는 휴리스틱 사용
▶데이터셋을 분할하여 의사결정 트리를 만드는 방법
1) 루트 노드는 분할이 일어나지 않았으므로 전체 데이터셋 표현
2) 의사결정 트리 알고리즘을 분할 하기 위해 특징 선택, 이상적으로 목표 클래스를 잘 예측하는 특징 선택
3) 특징의 고유 값에 따라 여러 그룹으로 분리되고 분기의 첫 번째 집합 형성
4) 각 분기별로 처리를 하면서 알고리즘이 종료 기준에 도달 할 때 까지 데이터를 분할 하고 정복해 나가며,결정 노드를 생성할 때마다 최고의 후보 특징을 선택한다. 분할 정복이 멈추는 조건 노드는 다음과 같다.
〮 노드에 있는 모든 예시가 같은 클래스를 가진다
〮 예시를 구별하는 특징이 남아 있지 않다.
〮 미리 정의된 크기 한도 까지 트리가 자랐다.
▶C5.0 알고리즘: 의사결정 트리의 수많은 구현 중 하나 , 문제 유형을 잘 처리하여 의사결정 트리르 생성하기 위한 산업 표준
|
장점 |
단점 |
|
대부분의 문제에 잘 실행되는 범용 분류기다. |
의사결정 트리모델이 레벨 수가 많은 특징의 분할로 편향될 수 있다. |
|
수치 특징 , 명목특징, 누락데이터를 다룰 수 있는 고도로 자동화된 학습 과정이다. |
모델이 과적합 또는 과소적합 되기 쉽다. |
|
중요하지 않은 특징은 제외한다. |
축-평행 분할에 의존하기 때문에 어떤 관계는 모델링이 어려울 수 있다. |
|
작은 데이터셋과 큰 데이터셋에 모두 사용될 수 있다. |
훈련 데이터에서 작은 변화가 결정 로직에 큰 변화를 초래 할 수 있다. |
|
(상대적으로 작은 트리에 대해) 수학적 배경없이 해석될 수 있는 모델을 만든다. |
큰 트리는 해석이 어렵고 트리가 만든 결정은 직관적이지 않아 보일 수 있다. |
|
다른 복잡한 모델보다 더 효율적이다. |
.
최고의 분할 선택
▶순도(purity): 예시의 부분집합이 단일 클래스를 포함하는 정도
▶순수(pure): 단일 클래스로 이뤄진 부분집합
▶ C5.0 은 엔트로피 사용, 클래스 값의 집합 내에서 무작위성 또는 무질서를 정량화
▶ 의사결정 트리는 엔트로피를 줄이는 분할을 찾고 궁극적으로 그룹 내 동질성 증가 시키려고 함
▶ 엔트로피는 비트(bits) 단위로 측정
▶가능한 클래스가 2개 뿐인 경우 엔트로피 값의 범위는 0에서 1이다.
▶클래스가 n개인 경우 엔트로피 범위는 0에서 log(n)이다.
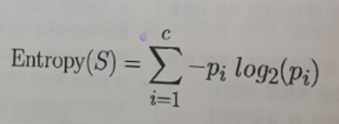
-S:데이터 세그먼트
-c: 클래스의 레벨 수
-pi : 클래스 레벨 i에 속하는 값의 비율
최고의 분할 선택
▶정보 획득량(information gain): 분할을 하기 위해서 최적의 특징을 결정하기 위해 엔트로피를 사용하는 것, 알고리즘은 각 특징별 분할로 인해 생기는 동질성의 변화 계산한다.
-특징 F의 정보 획득량은 분할 전 세그먼트(S1)과 분할로 생성된 파티션들(S2)의 엔트로피 차로 계산된다.
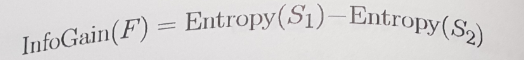
- 문제점은 분할 후에 데이터가 하나 이상의 파티션으로 나뉘는 점이다.=> Entropy(S2)를 계산하는 함수는 모든 파티션의 전체 엔트로피를 고려할 필요가 있다. => 각 파티션의 엔트로피에 파티션에 소속된 레코드의 비율에 따라 가중치를 부여한다.
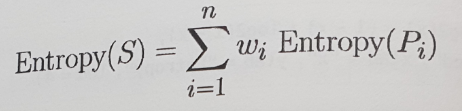
▶ 분할로 생기는 전체 엔트로피는 n개 파티션에 대해 각 파티션의 엔트로피에 파티션 속하는 예시 비율(wi) 로 가중치를 부여해서 합산한 것이다.
▶ 정보 획득량이 높을수록 이 특징에 대해 분할 한 후 동질적 그룹을 생성하기에 더 좋은 특징이다.
▶ 정보 획득량이 0인경우, 이 특징에 대해 분할을 하게 되면 엔트로피가 감소하지 않는다.
▶ 최대 정보 획득량의 경우, 분할 전 엔트로피와 정보 획득량이 동일하다. => 분할 후 엔트로피가 0이다. => 분할로 동질그룹 생성
▶의사결정 트리는 수치 특징에 대해 분할할 때도 정보 획득량을 사용한다.
▶수치 특징을 2-레벨 범주형 특징으로 줄여서 정보 획득량을 계산할 수 있다.
▶분할 시 최대 정보 획득량을 산출하는 수치 절단점을 선택한다.
의사결정 트리 가지치기
▶의사결정 트리의 가지치기 과정(pruning)
: 처음 보는 데이터에 일반화가 잘되게 트리의 크기를 줄이는 것
▶의사결정 트리의 조기 종료(early stopping) / 사전 가지치기(pre-pruning)
:결정이 특정 개수에 도달하거나 결정 노드가 포함하는 예시 개수가 아주 작은 숫자가 되면 트리의 성장을 멈추게 하는 것이다.
-단점) 감지하기는 힘들지만 트리가 크게 자랐다면 학습할 수도 있는 중요한 패턴을 놓친다. ->대안: 사후 가지치기
▶사후 가지치기(post- pruning): 의도적으로 트리를 아주 크게 자라게 한 후 트리의 크기를 좀 더 적절한 수준으로 줄이기 위해 잎 노드를 자른다.
-단점) 먼저 키우지 않고는 의사결정 트리의 최적의 깊이를 판단하기가 매우 어렵다.
▶하위 트리 올리기(subtree raising), 하위 트리 대체(subtree replacement)
: 전체 분기가 트리의 위쪽으로 옮겨지거나 좀 더 간단한 의사결정으로 대체한다.
분류 규칙 이해
▶분류 규칙(classification rules) :클래스를 레이블이 없는 예시에 할당하는 논리적인 if-else 문 형태로 표현
-분류규칙은 조건부 (antecedent)와 결론부(consequent)에 대해 명시
-”이것이 발생한다면 저것이 발생한다” 라는 가설을 구성
-조건부는 특정 특징 값들의 조합으로 이뤄짐, 결론부는 규칙의 조건을 만족할 때 배정할 클래스 값 지정
-규칙 학습자는 의사결정 트리 학습자와 비슷한 방식으로 사용
-미래의 행동을 위한 지식을 만들어내는 응용에 사용될 수 있음
〮기계 장비에 하드웨어 고장을 유발하는 조건의 식별
〮 고객 세분화를 위한 그룹의 주요 특징 기술
〮 주식 시장에서 큰 폭의 주가 하락이나 증가 상승에 선행하는 조건을 찾는 일
-규칙학습자의 장점) 〮 위에서 아래 방향으로 일련의 결정을 통해 적용되는 트리와 달리 규칙은 사실을 서술한 것처럼 읽을 수 있는 명제
〮 규칙학습자의 결과는 동일한 데이터에 대해 만들어지는 의사결정 트리보다 좀 더 단순하고 직접적이고 이해하기가 쉽다.
-규칙 학습자는 일반적으로 특징이 주로거나 전체적으로 명목형인 문제에 적용된다.
-희소한 사건이 특징 값 사이에 매우 특정한 상호작용에서 발생한다 하더라도 규칙학습자는 희소 사건을 잘 식별한다.
분리 정복
▶분리 정복(separate and conquer) : 분류 규칙 학습 알고리즘은 분리정복으로 알려진 휴리스틱 활용
-훈련 데이터에서 예시의 부분 집합을 커버하는 규칙을 식별하고 이 부분 집합을 나머지 데이터와 분리한다. 규칙이 추가되면서 데이터의 부분집합도 추가적으로 분리되고 전체데이터 셋이 다 커버되고 더 이상의 예시가 남아 있지 않을 때까지 진행된다.
▶ 규칙이 점점 더 큰 데이터 세그먼트를 점진적으로 소비하여 결국 모든 인스턴스 분류
▶ 커버링 알고리즘(covering algorithms) : 규칙이 데이터의 부분을 커버하는 것 같아 보임, 분리 정복 알고리즘은 커버링 알고리즘이라고도 함
1R 알고리즘
▶ZeroR : 글자 그대로 아무 규칙도 학습하지 않는 규칙 학습자, 특징 값에 상관없이 레이블 되지 않은 모든 예시에 대해 가장 흔한 클래스 예측
▶1R알고리즘 (One Rule and OneR) : 하나의 규칙을 선택하는 방식으로 ZeroR개선, 단순해 보이지만 잘 실행된다.
|
장점 |
단점 |
|
이해하기 쉽고 사람이 읽을 수 있는 하나의 경험적 규칙 생성 |
하나의 특징만을 사용 |
|
가끔 놀랄 만큼 잘 실행됨 |
아마도 너무 단순함 |
|
좀 더 복잡한 알고리즘의 기준점(benchmark)로 제공 될 수 있음 |
▶실행하는 방식 ) 1R은 각 특징에 대해서 유사한 값을 기준으로 데이터를 그룹으로 분리 -> 각 세그먼트에 대해 대다수 클래스를 예측 -> 각 특징에 기반을 두는 규칙의 오류율을 계산하고 최소 오류를 갖는 규칙을 단일 규칙으로 선정
Ex) 동물 데이터에 대한 알고리즘을 ‘이동 경로’ 규칙으로 하면 오류율이 2/15이고 , ‘털이 있는’ 규칙으로 하면 오류율이 3/15이다. ‘이동경로’ 특징이 오류가 적기 때문에 1R알고리즘은 이동경로 기반의 단일 규칙을 반환할 것이다.
리퍼 알고리즘
▶초기 규칙 학습 알고리즘의 문제점
❶알고리즘이 느리다 -> 큰 데이터셋이 증가하면서 알고리즘이 효과가 없어지게 되었다
❷잡음이 섞인 데이터에 대해 쉽게 부정확 해진다 .
▶해결방법
❶ IREP(Incremental Reduced Error Pruning) : 요하네스 펀크란츠와 게르하르트에 의해 제안,
사전 가지치기와 사후 가지치기 조합하여 사용, 복잡한 규칙을 기르고, 전체 데이터셋에서 인스턴스 분리하기 전에 규칙을 가지치기 한다.
❷RIPPER(Repeated Incremental Pruning to Produce Error Reduction): IREP 개선한것, 의사결정 트리의 성능에 필적하거나 능가하는
규칙 생성
▶RIPPER의 장단점
|
장점 |
단점 |
|
이해하기 쉽고 사람이 읽을 수 있는 규칙 생성 |
상식이나 전문가 지식에 위배되는 것처럼 보이는 규칙이 생길 수 있음 |
|
크고 잡음이 있는 데이터 셋에 효율적 |
수치 데이터 작업에 적합하지 않다 |
|
일반적으로 비교 가능한 의사결정 트리보다 좀 더 간단한 모델을 생성함 |
좀 더 복잡한 모델만큼 잘 수행되지 않을 수 있음 |
▶RIPPER알고리즘
-규칙 학습 알고리즘을 여러 회 반복하는 방식에서 진화
-규칙학습을 위한 효율적인 휴리스틱들이 여러 부분으로 연결 되어 있음
-알고리즘의 3단계)
❶기르기 : 규칙에 조건을 탐욕스럽게 추가하기 위해 분할 정복 기법사용, 데이터의 부분집합을 완벽하게 분류하거나 분할을 위한 속성이 없어 질 때까지 진행, 의사결정 트리와 비슷하게 다음 분할을 위한 속성을 식별하는데 정보 획득량 기준이 사용
❷가지치기 : 규칙의 구체성이 증가되어도 더 이상 엔트로피가 줄지 않을 때 가지치기 된다. 1단계와 2단계가 종료 조건에 도달할 때까지 반복된다.
❸최적화 하기 : 종료 조건은 규칙의 전체 집합이 다양한 휴리스틱으로 최적화 되는 지점
▶RIPPER알고리즘은 하나 이상의 특징을 고려할 수 있기 때문에 1R알고리즘보다 더 복잡한 규칙 생성 할 수 있다. 복잡한 데이터를 모델링하는 알고리즘 능력은 향상되지만 , 의사결정 트리처럼 규칙을 신속하게 파악하기 어려워진다.
의사결정 트리에서 규칙 구성
▶의사결정 트리에서 잎 노드에서 시작해서 분기를 따라 루트로 되돌아가면서 일련의 결정을 얻어 분류규칙을 정할 수 있고 하나의 규칙으로 결합 할 수 있다.
▶의사결정 트리의 단점) 생성된 규칙이 규칙 학습 알고리즘으로 학습된 규칙보다 더 복잡하다.
▶의사결정 트리에 사용된 분할 정복 전략은 규칙 학습자의 전략과는 다르게 결과를 편향시키지만 가끔 규칙을 트리에서 생성하면 계산적으로 더 효율적일 수 있다.
▶C5.0() 함수는 모델을 훈련시킬 때 rules = TRUE명시하면 분류 규칙을 이용해 모델을 생성하게 될 것이다.
무엇이 트리와 규칙을 탐욕스럽게 만드는가?
▶ 선입 선처리(FCFS, First-Come, First-Served)기반으로 데이터를 사용하기 때문에 의사결정 트리와 규칙 학습자는 탐욕학습자(greedy leaners)로 알려져 있다.
▶의사 결정 트리에서 사용되는 분할 정복 휴리스틱과 규칙 학습자에서 사용되는 분리 정복 휴리스틱 모두 한 번에 하나의 파티션을 만들고자 하고, 가장 동질적인 파티션을 찾고 난 후에 차선을 찾고, 모든 예시가 다 분류 될 때까지 계속해서 찾는다.
▶탐욕방식의 단점) 특정 데이터셋에 최적이고, 가장 정확하고, 최소 개수로 된 규칙을 생성하는 것을 탐욕 알고리즘이 보장하지 못한다.
▶탐욕학습자는 가장 쉽게 달성할 수 있는 목표를 빨리 이룸으로써 데이터의 한 부분집합에 대해 정확한 한 개의 규칙을 빠르게 발견할 수 있지만 전체 데이터셋에 대해 전반적인 정확도를 갖는 좀 더 섬세한 규칙들을 개발할 기회를 잃게 된다. 하지만 아주 작은 데이터 셋을 제회한 모든 데이터셋에 대해 계산적으로 규칙 학습이 불가능할 수 있다.
▶트리와 규칙 모두 탐욕 학습 휴리스틱 사용한다. 구분하기 좋은 방법은 분할 정복으로 특징에 대해 분할을 하면 분할에 의해 생성된 파티션은 재정복 되지 않고 단지 하위 분할만 된다는 것이다. 트리는 이전 결정의 이력에 의해 제한되지만 분리정복으로 규칙을 발견하면 규칙의 모든 조건으로 커버되지 않는 어떤 예시든지 정복 될 수 있다.
규칙학습자
①땅으로 걷고 꼬리가 있는 동물은 포유류다. (곰, 고양이, 개, 코끼리,돼지 ,토끼, 쥐 ,코뿔소)
②동물이 털이 없다면 포유류가 아니다. (새, 독수리, 물고기, 개구리, 곤충, 상어)
③ 그렇지 않으면 동물은 포유류이다. (박쥐)
▶규칙 학습자는 ‘털이 없는’ 결정으로 개구리를 재정복
▶규칙학습자는 궁극적으로 고려되었지만 이전 규칙들로 커버 되지 않는 경우를 관찰할 수 있으므로 인색한 규칙을 찾아낸다. 이러한 데이터의 재사용이 규칙학습자의 계산 비용기 의사결정에 드는 비용보다 좀 더 높다는 것 의미
의사결정 트리
①동물이 땅으로 걷고 털이 있다면 포유류이다. (곰, 고양이, 개, 코끼리,돼지 ,토끼, 쥐 ,코뿔소)
②동물이 땅으로 걷고 털이 없으면 포유류가 아니다 (개구리)
③동물이 땅으로 걷지 않고 털이 있으면 포유류이다. (박쥐)
④동물이 땅으로 걷지 않고 털이 없으면 포유류가 아니다. (새, 독수리, 물고기, 곤충, 상어)▶의사결정 트리는 기존 파티션을 변경할 수 없으므로 개구리르 자체 규칙에 배치해야 함
'STUDY > R을 활용한 머신러닝' 카테고리의 다른 글
| [R]3. 게으른 학습: 최근접 이웃 분류/k-NN알고리즘 (0) | 2020.08.22 |
|---|---|
| [R] 1. 머신 러닝 소개_머신 러닝 기원/머신 러닝 사례/머신 러닝 윤리/기계학습 방법/R을 활용한 머신 러닝 (0) | 2020.08.19 |
| [R]4.확률적 학습: 나이브 베이즈 분류 (0) | 2020.08.13 |
| [R] 2. 데이터의 관리와 이해 | 벡터/팩터/배열/행렬/데이터프레임/R을 활용한 머신러닝 (0) | 2020.08.13 |


